
Building a Smart Auto-Responder for FAQs
This article is co-authored with Lalitha Duru and Avneesh Sharma.
Generally, humans need answers to their questions efficiently and accurately. For a B2C brand/business, the timely resolution of such questions contributes a lot to customer retention and brand reputation. For resolving frequently asked customer queries, a lot of products currently offer an IVR like chatbot that asks the user to select from a limited set of options repeated multiple times, and navigating the user finally to the correct response. This experience can sometimes be frustrating and/or time-consuming for the customers. Hence, they choose to directly reach out to human support for their queries.
In these situations, having an automated way of “correctly” responding to frequently asked questions helps not only respond users quickly but also save human costs. It improves the user experience with the brand significantly.
Approach
There are two discrete approaches towards solving automated answering viz:
- Answer Inferencing: Interpret the response content of predefined FAQs to generate the correct answer
- Question Semantic Matching: Find the question from predefined FAQs that closely match the user query and respond with the corresponding answer
After looking at some real world scenarios[1], drawbacks of using the first approach are as follows:
- Similar answers to significantly different questions
- Hierarchical nature of FAQ data
- Responses may have incomplete context
The questions were semantically more dissimilar and unique. Hence, we chose to solve this problem using question semantic matching technique rather than answer inferencing technique.
Following are the solutions we explored for semantic matching:
- Apache OpenNLP
The Apache OpenNLP library is a machine learning based toolkit for the processing of natural language text. It supports the most common NLP tasks, such as language detection, tokenization, sentence segmentation, part-of-speech tagging, named entity extraction, chunking, parsing, and coreference resolution.
In order to use this for semantic matching, we need to first train the categorizer model using BagOfWords or n-Gram approach. On successful training, the user’s question is subjected to the following steps to match the best question:
- Word2Vec with WMD (Word Movers Distance)
The main ingredient of WMD is the word vectors also known as word embeddings. These are real number vectors representing these words in multi-dimensional space. These vectors are calculated by applying neural network models on real-world text documents.
For example, Word2Vec is one such model developed by google by going through a large google news dataset. This pre-trained model was used to generate a set of word vectors for a given sentence. We then applied the WMD algorithm to find the best match, visual representation of which is shown below:
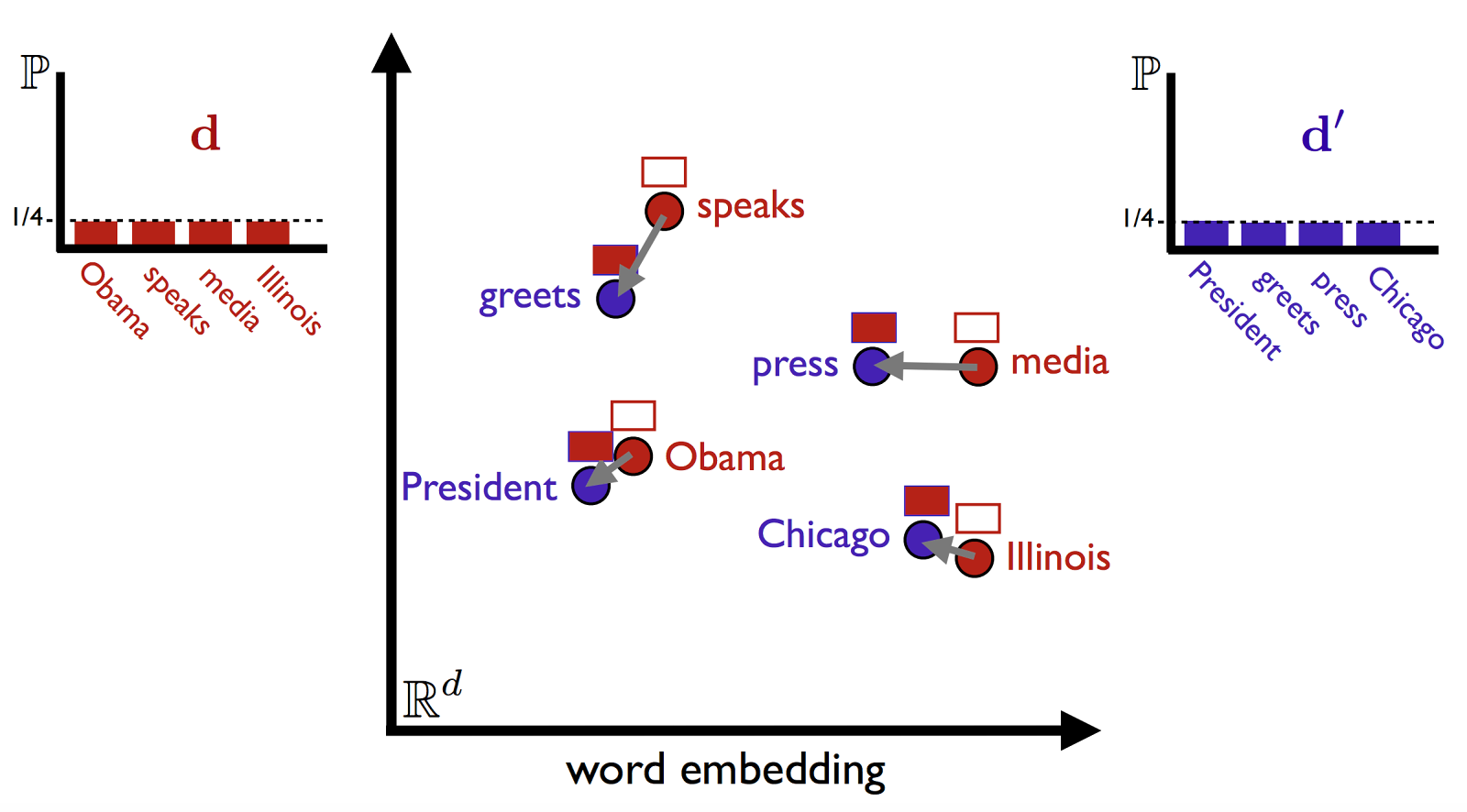
Image credit: Vlad Niculae
The first two approaches primarily focused on the words present in the sentence rather than the contextual meaning and significance of the word in the sentence.
The following four approaches are different sentence encoder models which generate a multi-dimensional vector representation of an input sentence. These encoders differ from word-level embedding models in that they are trained on a number of natural language prediction tasks that require modeling the meaning of word sequences rather than just individual words. To measure the semantic similarity between two sentences, we calculated the cosine similarity between the resulting vectors.
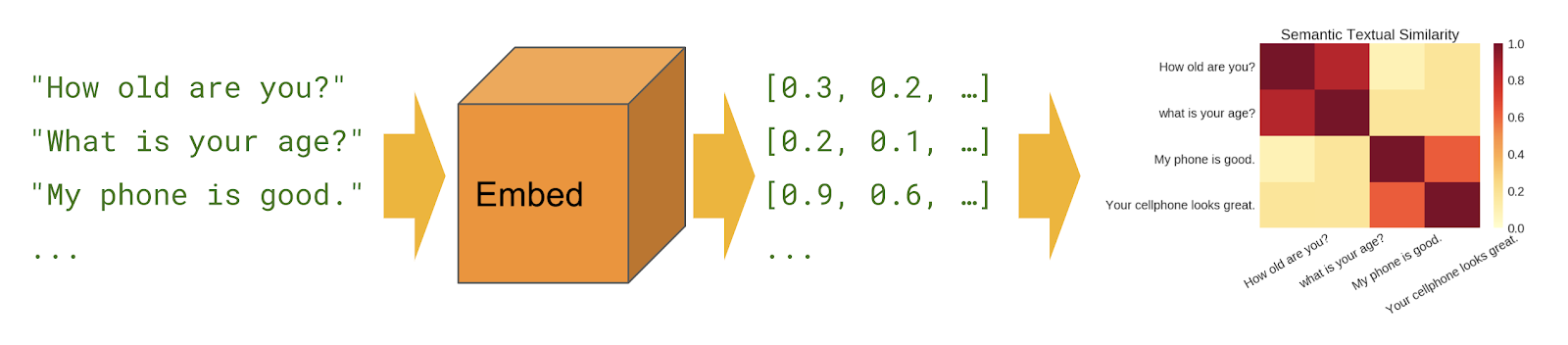
Image credit: TensorFlow
- USE (Universal Sentence Encoder)
The universal sentence encoder encodes text into high-dimensional vectors that can be used for text classification, semantic similarity, clustering, and other natural language tasks.
The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length English text and the output is a 512-dimensional vector. The USE model is trained with a deep averaging network (DAN) encoder.
- InferSent from Facebook
InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language inference data and generalizes well to many different tasks. The encoding architecture is a bi-directional LSTM (long short-term memory) with max-pooling that uses pre-trained word vectors as base features.
- BERT (Bidirectional Encoder Representations from Transformers)
BERT provides dense vector representations for natural language by using a deep, pre-trained neural network with the Transformer architecture. This model has been pre-trained for English on Wikipedia and BooksCorpus.
For training, random input masking has been applied independently to word pieces. We used the Uncased Bert-Base model for our evaluation. The input is variable-length English text and the output is a 768-dimensional vector.
- Sentence Transformers
A modification of BERT using the Siamese network to produce sentence embeddings trained on NLI and STS datasets.
Model Evaluation
We started sanity testing of all the models and found that the OpenNLP model significantly underperformed even at basic matching tasks primarily due to the following limitations:
- Similar words in vocabulary are most likely to be treated differently (i.e., “amazing” and “superb” have very similar meanings but are treated differently by the model).
- Word order can sometimes ignore the context. For example: “Record the play” and “Play the record” have high similarity scores in spite of different meanings.
Hence we discarded the model from further evaluation.
In order to evaluate the models in a standard fashion, we realized that we needed a large dataset covering a variety of domains, having pairs of sentences already identified as similar or dissimilar.
The Quora Question Pair (QQP) dataset was satisfying this criteria sample of which is below:
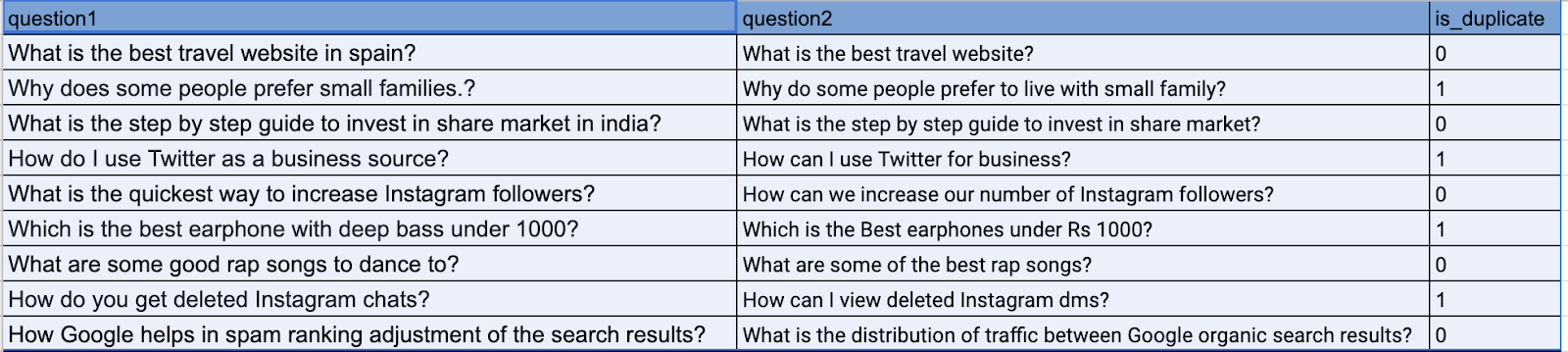
Column “is_duplicate” is 1 for similar sentences and 0 for dissimilar sentences.
On preliminary manual analysis of the dataset (sample above), we found that the pairs of similar sentences indeed fit the similarity criteria above. However, a reasonable subset of the pairs marked as dissimilar, although might actually be dissimilar enough for solving quora question matching, were quite similar for our problem statement. Hence, we generated pairs of dissimilar sentences by randomly pairing questions from the QQP dataset.
We subjected each of the models to the newly prepared dataset of similar and dissimilar question pairs and plotted the distribution function of the score generated by the model. For similar question pairs, we plotted CCDF (Complementary Cumulative Distribution Function) except for Word2Vec which has CDF (Cumulative Distribution Function). For dissimilar pairs, we plotted the CDF except for Word2Vec which has CCDF.
Evaluation Results
- Word2Vec with WMD
Similarity measure is euclidean distance. Lesser distance implies higher similarity.
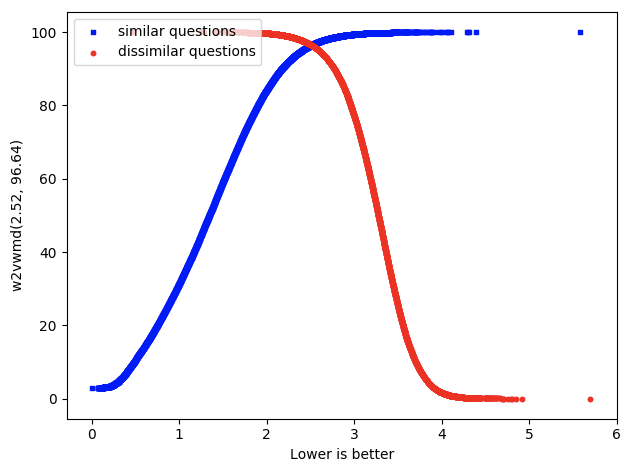
The two curves intersect at (2.52, 96.96).
- Universal Sentence Encoder
Similarity measure is cosine similarity. Higher score implies higher similarity.
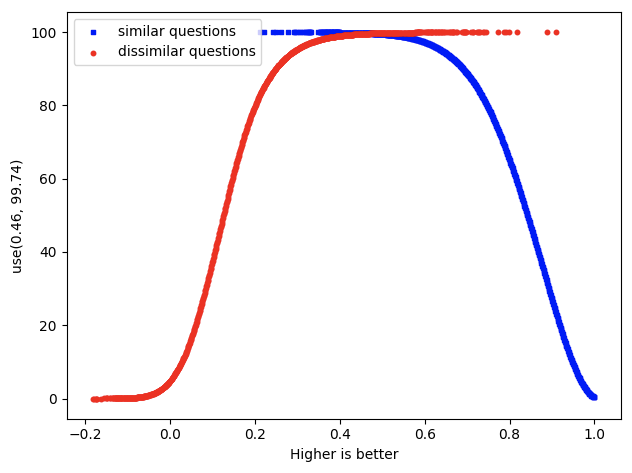
The two curves intersect at (0.46,99.74).
- Infersent – Sentence Encoder by Facebook
Similarity measure is cosine similarity. Higher score implies higher similarity.
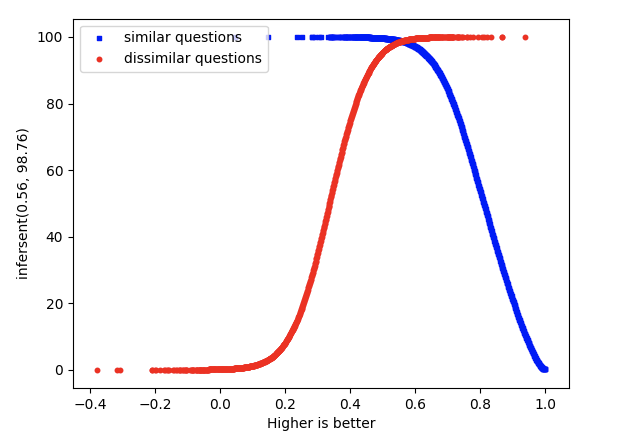
The two curves intersect at (0.56,98.76).
- BERT Embeddings
Similarity measure is cosine similarity. Higher score implies higher similarity.
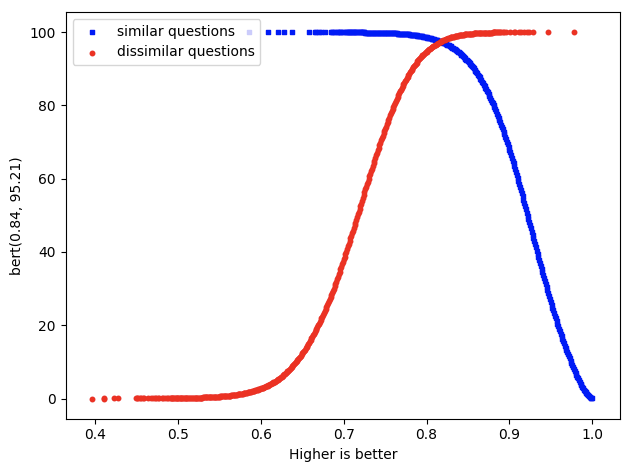
The two curves intersect at (0.84,95.21).
- Sentence Transformer
Similarity measure is cosine similarity. Higher score implies higher similarity.
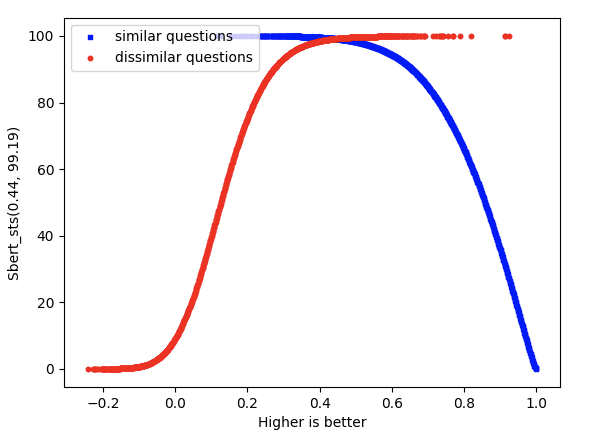
The two curves intersect at (0.44,99.19).
The ideal result of our evaluation would have been a perfectly rectangular plot. Such a graph would be possible if similarity scores for all similar questions, comes out to be 1 and for all dissimilar questions the score comes out to be 0. In reality, the higher intersection and a flatter top would imply that the model is more accurate in its predictions and has fewer false positives.
Looking at the results, we chose the Universal Sentence Encoder and Sentence Transformer models as the winners of our evaluation.
To choose one clear winner out of Sentence Transformer and USE, we subjected these models to real world FAQ data. The performance of both the models turned out to be quite similar, each having an edge over the other in specific scenarios.
Ensemble
In order to combine the best of both worlds, we came up with an ensemble approach as shown in the diagram below:
We subjected the new ensemble model to QQP dataset and got the following cumulative function plot:
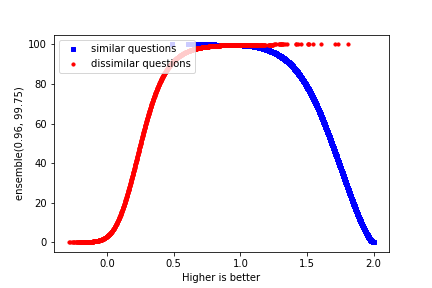
The two curves intersect at (0.96, 99.75).
Upon evaluating this approach on the real world data, it continued outperforming the individual models.
Conclusion
We started solving our problem with Apache OpenNLP and moved on to word vector generators. However, we got best performance using sentence vector generators and specifically with USE and Sentence Transformers. It was a tight call to choose between the two models with both being evenly matched. Hence we explored the ensemble approach to combine the best of both worlds. As expected, the results improved significantly in the QQP test and real-life scenarios.
References
- Create your own chat bot in Java using Apache OpenNLP | Artificial Intelligence | Natural Language Processing
- Apache OpenNLP
- Word Mover’s Distance in Python
- universal-sentence-encoder
- UKPLab/sentence-transformers
- facebookresearch/InferSent
- Bidirectional Encoder Representations from Transformers (BERT)
- http://qim.fs.quoracdn.net/quora_duplicate_questions.tsv
[1] Real world tests used following FAQs:
- https://www.swiggyassist.in/faq
- https://support.bookmyshow.com/support/solutions
- https://www.hotstar.com/in/faq


