
Introducing TesseractDB™ Generation 3
This article is co-authored with Lalitha Duru, Hardik Shah, and Avneesh Sharma.
We’ve come a long way since CleverTap was founded in 2013. Today, we process over 36 billion data points a day, spread out over four data centers. We reach 3 billion devices globally, and serve close to 1200 customers. All that data needs to be stored, processed, and be readily available for querying by our customers. When our customers use us for engaging with their users, they need to have results within seconds, so as to provide real-time personalized experiences that drive their business. One might ask, how did we accomplish this technically? Do we spend millions of dollars on our infrastructure? What’s our secret sauce?
We invented TesseractDB™ in 2013 as the world’s first purpose built database for user engagement and retention. It made storing user data accessible and affordable so that our customers could unlock its full potential to truly understand their users, and to hyper-personalize each interaction with them.
Generation 2
Back in 2018, when we re-architected our database first written in 2013, we introduced:
- Transparent compression
- Sharding
- Faster querying
At this point, the storage engine used a row based approach. That meant all event properties were stored in one single contiguous block. Moreover, all data was stored in-memory. As a result, even if we had to query only a small part of this block, we’d have to uncompress the entire block, since operating on compressed data isn’t feasible without extensive metadata. Using a combination of different compression techniques, we were able to overcome the overhead introduced, along with improving query time! Certain types of queries were further accelerated by a factor of 2 or more!

This generation of our storage engine helped us scale to massive traffic, but if there wasn’t a better upgrade, we wouldn’t have been writing this blog post 😊
New Requirements
So what triggered the third major revision of TesseractDB™? Well, one of the most sought after requests from our customers was to store more data. After all, context can be built only by knowing one’s users. This could be accomplished by retaining their entire user history, and not just the last six months or so. Of course, this would then need to be queryable, without sacrificing performance. At first, we thought that this could be accomplished easily by throwing more resources at the problem (which literally translates to more compute resources), however, that would have increased the cost significantly.
We wanted to come up with a cost effective way of storing larger datasets, while being able to query it efficiently.
Generation 3
We started tackling some of the drawbacks with our previous generation:
- Decompressing unwanted data blocks
- Storing everything in-memory
With this in mind, we reinvented our storage protocol.
Network Columnar Format
TesseractDB™ Generation 3 is powered by a brand new protocol, the Network Columnar Format (or NCF for short). This storage protocol was inspired by RCFile, Apache ORC, and a few others. Being a columnar storage format, it was a major transition for us. Each storage format had its own benefits. The earlier row based approach excelled when all of the data was being queried (such as exporting data), while the new columnar approach excelled for almost all real time queries, which don’t require all data to be queried.

Main Features
Lazy Decompression
When processing a stream of data, there might be a part of it that we’d like to skip over. This might be due to a number of factors, such as knowing beforehand that it won’t satisfy a particular criteria. This allows us to process queries even faster!
Mixed Data Types
Usually, the data type for an event property is fixed. However, occasionally, the data type might change, say from an integer to a string (although they represent the same value). We don’t transform values, and prefer to store the original types.
On the Fly New Column Definitions
Surprisingly, most columnar storage protocols don’t support defining new columns midway (after initializing their encoders). NCF allows one to add and remove columns on the fly, without adding any additional overheads.
Disk Error Resilience
In the event of corruption, say on disk storage, or in the cloud, file contents might get corrupted. At such times, it should be easy and trivial to skip through only the corrupted portion, and resume immediately after, within the same file.
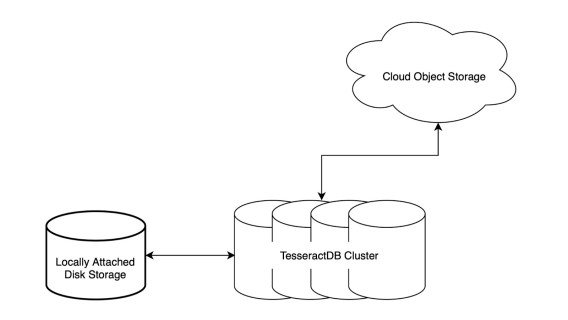
Optimized for Object Storage & Point Lookups
Since object storages such as Amazon S3 support byte range requests, an entire file doesn’t need to be retrieved. After retrieving NCF’s metadata, it tells us precisely which byte ranges of the file should be retrieved. As a happy coincidence, this allows us to pinpoint related data within a large NCF file 😊
Challenges
One of the largest problems with object storages is that they impose a high latency on any retrieval operation (our benchmarks indicated an average of 100 ms). With too many objects, there’s too much latency. On the other hand, fewer objects, and the metadata becomes too large. To combat this, we decided to build a variable date range file policy, which allowed us to combine fixed date ranges of related data in a single file. Choosing the appropriate time window was easy for us, because hey, we have tens of thousands of queries executed each day!

We observed that the majority of our customers’ queries were for either 1 day, 15 days or 30 days, as depicted in the graph above. When NCF’s metadata and file structure was designed, this was taken into account.
The design and protocol format of NCF will be elaborated in a future blog post.
Not Everything Needs To Be In-Memory
With the efficiency of NCF and its ability to pinpoint data location, we explored various storage options, including cloud object storage (NCF was built with this in mind). Today, only a part of the data resides in memory, and even local to that node. Whenever a query comes in, NCF’s metadata is able to tell us exactly which bits of a file contains the required data, and only that portion is retrieved. Upon arrival, before the data is decompressed, NCF’s metadata is able to tell us whether the given dataset contains the desired data or not, and can completely skip decompressing values that are known to not satisfy the query criteria!
The Transition
When we started planning the transition for our customers in April 2021, we found that the total addressable dataset was roughly over 40 petabytes. Of course, not all of it belonged to a single customer. Therefore, we decided to transition each of our clusters (one cluster holds data for one or more customers) one at a time. At first, we decided to start small, and move just one cluster. Once we built confidence in the entire process (we pretty much automated everything with AWS Systems Manager), and orchestrated transitions of several clusters together, which occasionally involved more than 150 instances at a time!
Within the span of a few months, we transitioned all our customers seamlessly, and enabled them to leverage the power of TesseractDB™ Generation 3!
Conclusion
For our most popular analytical queries, TesseractDB™ Generation 3 is twice as fast compared to our second generation engine. With the addition of NCF, it sets the foundation to scale out to stateless compute instances in the future. More details about our design decisions will be posted in the upcoming months. Stay tuned!



Es la publicidad en línea un área de oportunidad en México. - Gadgets México
[…] líder de retención y engagement del cliente multicanal, con su tecnología más avanzada TesseractDB™, actualmente impulsa más de 10,000 aplicaciones móviles en tres millones de dispositivos en todo […]