
Maximising Your A/B Test Outcomes with Multi Armed Bandits
Traditional A/B testing has stuck around for decades and is an important tool in a marketer’s toolkit, but there also exist other techniques for testing, some that even perform better and combat the flaws of A/B testing. Let’s explore them in this blog.
Suppose you’re a marketer and you want to run a campaign to maximise clicks by sending notifications to users who have opened your website. These are your options for the notification text:
- Get 50% off on your next purchase, click to see your offers now!
- Buy 1 get 1 free on premium products!
- Big sale! Check out these items before they’re out of stock!
- 50% discount on your favorite products! Avail now!
Now, prior to sending the campaign, you don’t know how each one will perform. Usually, a marketer would do one of these:
- Select one of these based on your intuition and hope it works well.
- Do an A/B test with these campaign texts, and select a winner after some time, based on which is getting the most clicks.
Generally, a marketer will use A/B testing.
A/B testing essentially involves 2 stages:
- Explore the options on a small percentage of users
- Exploit the information gathered from the exploration stage by sending the winning variant to the rest of the users who haven’t received any options
Unfortunately, A/B testing comes with flaws.
- Did you explore each variant enough?
- Was the campaign sent to enough users before selecting a winning variant?
- Are seasonal trends being accounted for?
What if, based on new information, you could keep trying different variants and continuously give preference to the best performing one?
Can you continuously Explore and Exploit?
Here is where Multi Armed Bandit approaches become useful.
The Multi Armed Bandit (MAB) problem is a common reinforcement learning problem, where we try to find the best strategy to increase long-term rewards. Multi Armed Bandit performs continuous exploration along with exploitation.

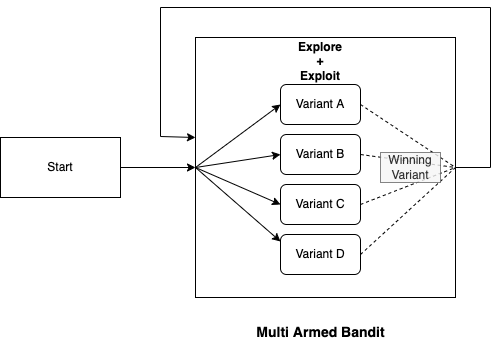
That is, even while testing out all the variations, MAB ensures that the highest possible number of clicks are received.
Instead of an A/B test, where you run the test, then select the best alternative and run with it, MAB optimises and drives more traffic to the best alternative while running the test, hence reducing missed opportunities.
Let’s look at various MAB techniques using Python code and an example dataset
Full code available here: https://github.com/SidJain1412/MultiArmBanditExploration
Sample Data:
Consider a scenario where we have 4 ads, with approximate CTRs (Click-Through Rate = number of clicks/ number of views) of:
Ad 1: 12%, Ad 2: 14%, Ad 3: 10%, Ad 4: 11%
This is not known to us before running the campaign. If we knew this, we would show Ad 2 to all users and get the highest possible click rate.
These ads are shown to people opening your website, and the campaign runs for 10 days. You get approximately 1000 users everyday, for a total of 10000 users.
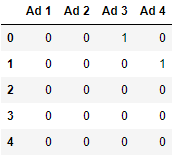
Each row is a user, 1 means that user clicked on that specific ad, 0 means they didn’t. Some users clicked on no ads, some clicked on multiple.

As we can see from this distribution, Ad 2 has the highest click-through rate.
If this was already known to the marketer, they would show Ad 2 to all users, and get the highest possible number of clicks, i.e. 1390.
But this isn’t known, so they can solve this problem with MAB, maximizing the number of clicks while also exploring the variants to find the best one.
To compare against MAB techniques, let’s look at random selection and simple A/B testing first.
Random Selection
Let’s see what happens if we select ads randomly for each user (as a baseline):
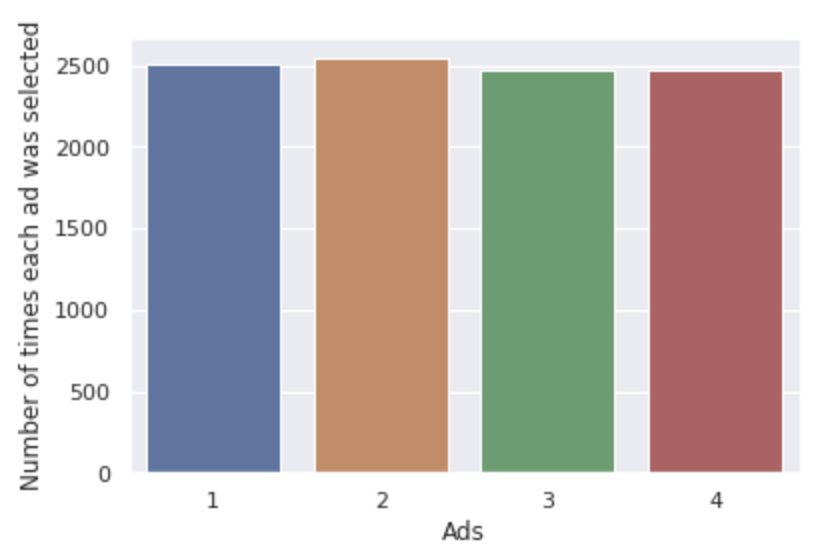
Our total clicks with this method is 1185.
A/B testing:
For a fair comparison, let’s consider a scenario where you do AB testing for the ads, and select a winner once 10% of the users have been shown ads.
Since we are showing the ad to ~10000 users over 10 days, we run the AB test for 1 day (exploration), then show the determined winner for the rest of the 9 days (exploitation).
Code snippet:
Click-through rate for each ad after 1 day:

According to this, we select the best ad to be ad number 1, and show it to the remaining users.
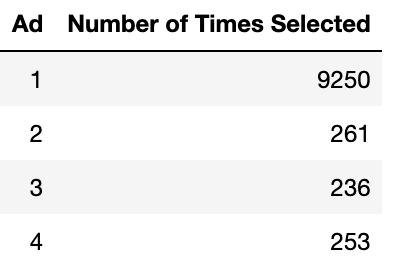
The total number of clicks we receive with this method is 1193. A very small improvement over random selection.
The problem here is that based on the performance on day 1, we assumed Ad 1 would perform well on the remaining days as well. This isn’t the case (as Ad 2 has the highest overall click-through rate). This happens in real world use cases as well, due to seasonality, day of the week, and many other external factors.
Multi Armed Bandit algorithms:
There are different algorithms to solve the MAB problem. In this article, we will talk about 2 popular ones.
Upper Confidence Bound (UCB)
UCB is based on assigning a confidence interval to each ad based on each iteration. It is a deterministic algorithm (i.e. No randomness). A confidence interval is basically a range of values in between which the actual Click %age of the ad lies.
UCB is a deterministic algorithm for Reinforcement Learning that focuses on exploration and exploitation based on a confidence boundary that the algorithm assigns to each variant on each round of exploration.
Steps:
- Assume a starting confidence band for all bandits
- Try each bandit a few times (atleast once)
- Pick the bandit with the highest confidence band (if multiple with the same value, pick randomly)
- Run that specific bandit (ad variant). If the bandit gets a reward, the confidence interval moves towards the actual success distribution and becomes smaller, or else it moves away; thus shrinking its confidence interval.
- The upper confidence bound for that bandit is now closer to its actual average reward.
- Repeat steps 3, 4 and 5 for n iterations
- After some time, the highest confidence band bandit will come out on top and will keep being used again and again
Code snippet:
Visualisation of UCB:
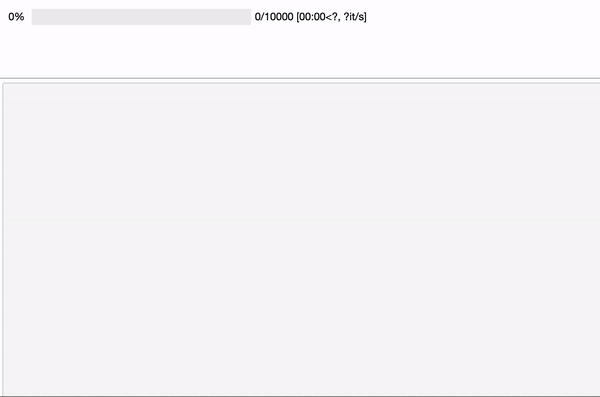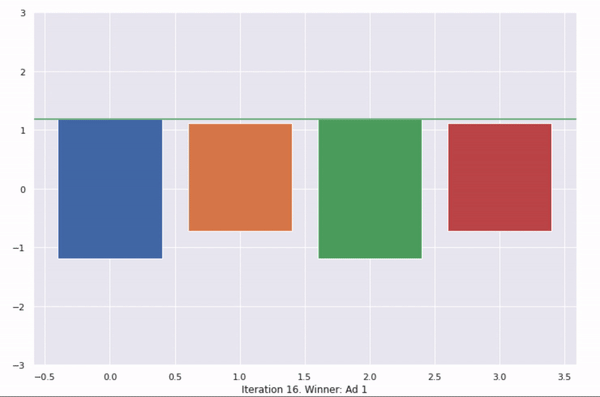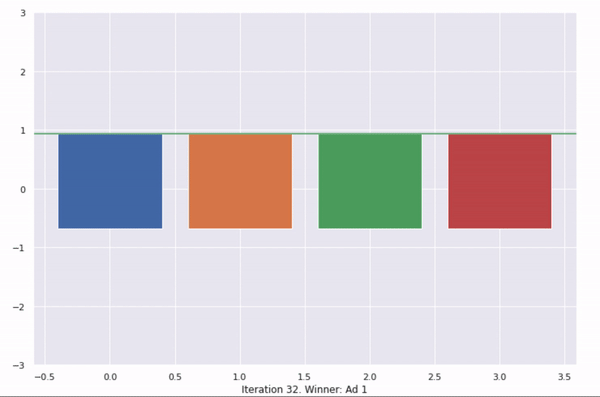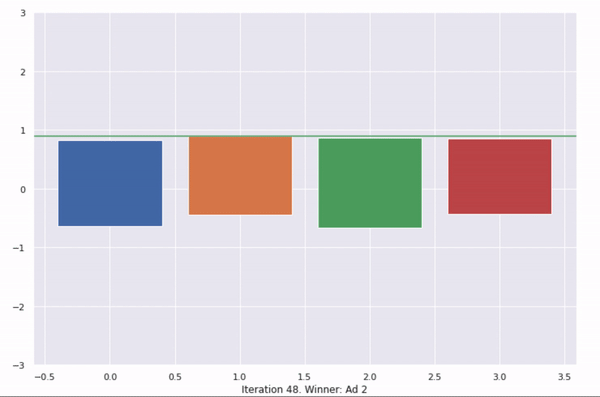
This shows 50 iterations of UCB. At every iteration, a new upper bound is calculated for each ad. This is an optimistic probability of the ad being clicked. The ad with the highest upper bound is selected and shown to the user.
With more iterations, more information is known about the actual average click-through rate of each ad, hence the probability distribution gets thinner and moves towards the actual average with every iteration.
Results with UCB:
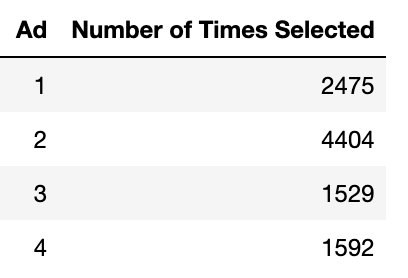
The best ad (ad 2) was selected frequently and the total reward was found to be 1275 (as compared to the max of 1390, random selection reward of 1185, and A/B test reward of 1193). A definite improvement over random selection and A/B testing.
Thompson Sampling:
Thompson Sampling uses the Beta Distribution to intelligently decide a range of values where the actual success percentage of a variant lies. It is a probabilistic algorithm (i.e. it includes some randomness).
At the start of exploration, the ranges for each variant are wide, but as we go on collecting data during experiments, the distributions get updated and the range gets smaller; i.e. We can say with higher confidence that a certain variant has a certain success percentage.
Steps:
- Create 2 arrays of 0s to store number of wins (Nwins) and number of losses (Nloss) for each ad.
- Iterate over each user.
- For each ad, get a random value from the betavariate distribution for that ad (between 0 to 1) by using the Nwins and Nloss for that ad.
- Select the ad with the highest value and send that to the user.
- Update Nwins and Nloss for that ad. This will change that ad’s beta distribution for the future.
- Let the experiment run and the best ad will get selected most of the time.
Code snippet:
Visualization of Thompson Sampling:
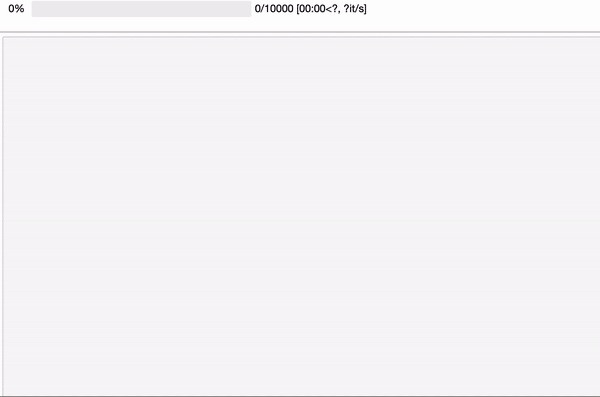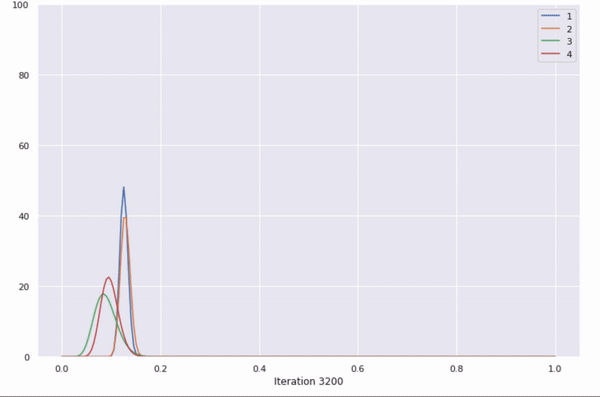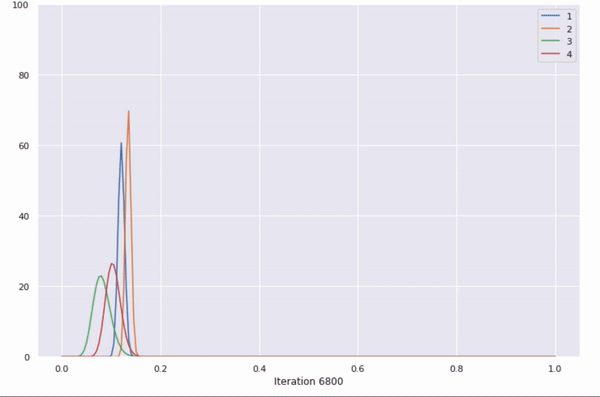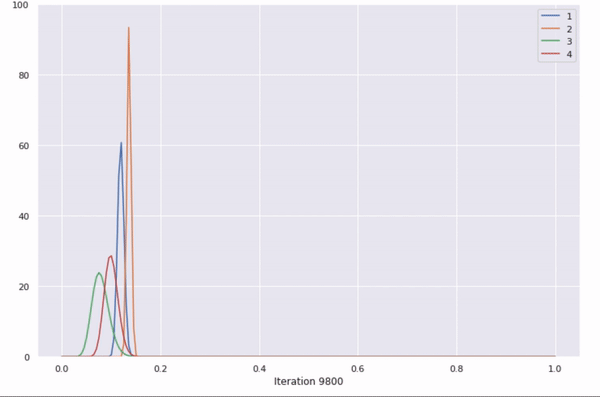
This GIF shows the changing beta distributions for an ad being selected.
The beta distributions are updated with each run, and successful selections of an ad make its beta distribution sharper.
Further explanation: The ad to be shown is chosen by picking the max of a random sample of these 4 beta distributions. The more times an ad gets selected, the sharper its beta distribution gets. With each iteration, the probability of the best ad being selected increases.
Results with Thompson Sampling:

Clearly, the best ad (ad 2) was selected very frequently, and the total reward was found to be 1310 (as compared to the max possible of 1390, random selection reward of 1185, A/B test reward of 1193, and UCB reward of 1275). Impressive results, and a sizeable improvement over UCB.
Comparison and Conclusion:
Clearly, both techniques outperformed random selection, and Thompson Sampling beat UCB by a big margin.
1. When is UCB a better choice?
UCB is deterministic, i.e. there is no randomness. Multiple runs will give the exact same result. This could be important in some cases. UCB also emphasizes exploration a lot more than TS, so if you think the best variant could very easily change over time, you may want to use UCB.
2. Which of the two is easier to productionize?
UCB has to be updated at every iteration, whereas Thompson Sampling updates can be delayed and it will still perform well. Updating upper bounds at every iteration is very tricky at scale, hence TS is easier to use in the real world, plus it usually performs better than UCB.
3. Why use UCB or TS when simple A/B testing can give decent results?
A/B testing is still useful when your experiment has to run for a very short time. It may not be possible to continuously experiment due to shortage of time.
Multi armed bandit methods continuously explore possibilities, so even if external circumstances change mid-experiment, the algorithm will strive to find the best variant.


